
Einleitung
Als CIO oder IT-Manager stehen Sie täglich vor der Aufgabe, generative KI-Werkzeuge gewinnbringend, verlässlich und risikofrei in Ihre Unternehmensprozesse zu integrieren. Wer generative Bildmodelle bisher für Marketing, automatisiertes Interface-Design oder technische Dokumentationen evaluierte, stieß jedoch schnell auf ein frustrierendes Phänomen: Die generierten Bilder wirkten fotorealistisch, doch jeglicher enthaltene Text glich einer unleserlichen, fragmentierten Geheimsprache.
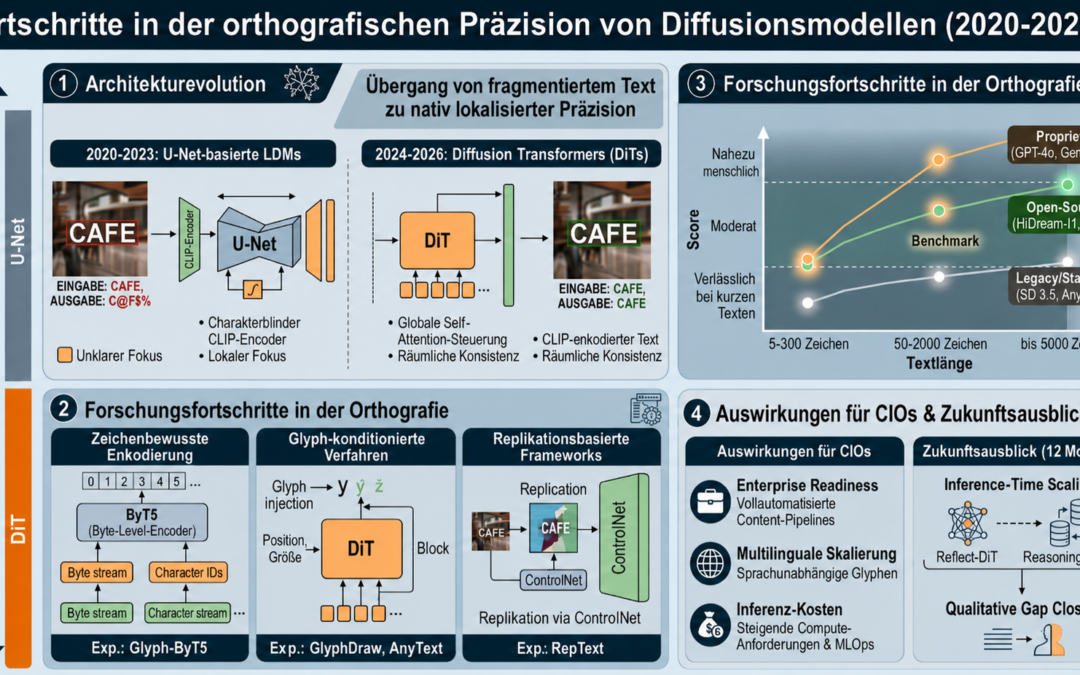
Die Analyse der Architekturevolution von 2020 bis 2026 zeigt unmissverständlich: Wir stehen an einem Wendepunkt, an dem die orthografische Präzision endlich mit der visuellen Ästhetik gleichzieht. Für IT-Entscheider bedeutet dies, dass Bildgeneratoren reif für den produktiven Unternehmenseinsatz werden – vorausgesetzt, man setzt auf die richtige Architektur.
Stand der Technik: Der Paradigmenwechsel vom U-Net zum Diffusion Transformer
Das primäre Problem der fehlerhaften Textgenerierung war kein Mangel an Trainingsdaten, sondern ein mathematisches Konstrukt. Traditionelle latente Diffusionsmodelle (LDMs) bauten auf Faltungs-basierten U-Net-Architekturen auf. Diese nutzen zwar Cross-Attention-Schichten zur Integration von Textprompts, stoßen jedoch bei komplexen räumlichen Abhängigkeiten an ihre Grenzen. Das Resultat im kontinuierlichen Raum waren typische Fehlermuster wie Buchstabensubstitutionen, Wegfälle oder räumliche Fragmentierungen, da Schrift intrinsisch diskret und regelgebunden ist.
Der technologische Durchbruch gelang im Jahr 2024 mit dem Übergang zu reinen Transformer-Architekturen, den sogenannten Diffusion Transformers (DiTs). Modelle wie SD3/MMDiT , FLUX.1 und das Open-Source-Flaggschiff HiDream-11 (welches mit massiven 17 Milliarden Parametern operiert) ersetzten das U-Net-Backbone durch reine Transformer-Blöcke. Diese globale Self-Attention-Steuerung ermöglicht räumliche Konsistenz über weite Distanzen und stabilisiert die Textkohärenz entscheidend.
Dennoch zeigt der aktuelle STRICT-Benchmark von 2025 eine deutliche Leistungslücke im Markt:
| Modell-Klasse | Getestete Textlänge | Charakteristik |
| Proprietär (GPT-4o, Gemini 2.0) | bis 5.000 Zeichen | Überlegene Leistung; near-human bei kurzen Texten |
| Open-Source (HiDream-11, FLUX) | 50–2.000 Zeichen | Moderate Leistung; gut bei mittleren Längen |
| Legacy/Standard (SD 3.5, AnyText2) | 5–300 Zeichen | Verlässlich nur bei sehr kurzen Textsequenzen |
Aktuelle Forschung: Ansätze zur Überwindung der „Charakterblindheit“
Die Forschung der letzten Monate zeigt, dass das Problem tief im Text-Encoding verwurzelt liegt. Der weit verbreitete CLIP-Encoder operiert „charakterblind“ (character-blind). Er verarbeitet Wörter als unteilbare Tokens – dem Modell fehlen schlicht die Informationen über die interne Buchstabenfolge. Die aktuelle Wissenschaft reagiert darauf mit drei vielversprechenden methodischen Ansätzen:
- Zeichenbewusste Enkodierung (Character-Awareness): Das Modell Glyph-ByT5 nutzt einen ByT5-Encoder auf Byte-Ebene. Indem das Modell intrinsisch zeichenbewusst agiert, stieg die Spelling-Genauigkeit in Design-Benchmarks dramatisch von unter 20 % auf nahezu 90 %.
-
Glyph-konditionierte Verfahren: Frameworks wie GlyphDraw und GlyphControl injizieren vorgerenderte Glyphen direkt in den Diffusionsprozess, um präzise Positions- und Größenausrichtungen zu erzwingen. AnyText nutzt hierzu spezialisierte Hilfsmodule für die simultane Textbearbeitung.
-
Replikationsbasierte Frameworks: Modelle wie RepText verfolgen den Ansatz „Imitation statt Retrieval“. Über sprach-agnostische Glyph-Replikation via ControlNet können monolinguale Modelle befähigt werden, multilinguale Inhalte (wie Arabisch oder CJK-Zeichen) fehlerfrei darzustellen. Design Diffusion versucht zudem, den Trade-off zwischen rein visueller Ästhetik und orthografischer Präzision über einstufige End-to-End-Systeme aufzuheben.
Drei wesentliche Auswirkungen auf die Entwicklung generativer KI-Werkzeuge
- Das Ende komplexer Design-Workarounds: Bisher mussten IT-Abteilungen fehlerhafte KI-Bilder über nachgelagerte Programmierbroutinen (z. B. automatisierte Bildbearbeitungsskripte) mühsam mit korrektem Text überlagern. Die native Textintegration über DiT-Architekturen macht diese fehleranfälligen Pipelines obsolet. Text wird nun als semantisch-strukturelle Einheit begriffen, was vollautomatisierte Content-Pipelines im Enterprise-Bereich erst möglich macht.
- Skalierung der multilingualen Internationalisierung: Dank replikationsbasierter Ansätze wie RepText entfällt die Notwendigkeit, gigantische, kulturspezifische Bildmodelle für jeden Markt separat zu trainieren. Ein einziges Kernmodell kann globale Kampagnen inklusive komplexer, nicht-lateinischer Schriftsysteme präzise rendern.
- Steigende Compute-Kosten und veränderte MLOps-Anforderungen: Skalierungsebenen von 17 Milliarden Parametern (wie bei HiDream-11) bedeuten für CIOs drastisch steigende Anforderungen an die Inferenz-Infrastruktur. Zudem müssen MLOps-Szenarien um spezialisierte Benchmarks wie STRICT erweitert werden, um die typografische Qualität vor dem Deployment automatisiert zu auditieren.
Exemplarische Prognose für die nächsten 12 Monate
Die reine Skalierung von Modellparametern stößt an wirtschaftliche Grenzen. Da die Long-Range-Konsistenz bei extensiven Textpassagen nach wie vor der gravierendste Flaschenhals ist, wird das nächste Jahr im Zeichen des Inference-Time Scaling stehen. Wir werden die verstärkte Integration von Reasoning-LLMs (wie DeepSeek-R1) als strategische Planungskomponenten sehen. In Kombination mit Ansätzen wie Reflect-DiT, die mittels In-Context-Reflexion ihre eigenen Rendering-Entwürfe während der Generierung korrigieren, wird sich die qualitative Lücke zwischen Open-Source- und proprietären Systemen bis Mitte 2027 drastisch schließen.
Schlussfolgerung
Die Ära, in der wir über verunglückte, deformierte KI-Buchstaben schmunzeln konnten, ist vorbei. Der Übergang zu Diffusion Transformers hat das technologische Fundament für verlässliche Corporate-Tools gelegt. Für CIOs und IT-Manager ist es an der Zeit, generative Grafikwerkzeuge neu zu bewerten: Messen Sie Systeme nicht mehr nur an ihrer gefälligen Bildästhetik, sondern prüfen Sie deren zeichenbewusste Präzision im Core-System. Die orthografische Präzision ist im Enterprise-Sektor angekommen – stellen Sie sicher, dass Ihre IT-Infrastruktur bereit dafür ist.
Glossar: Die 5 wichtigsten Abkürzungen im Überblick
-
DiT (Diffusion Transformer): Eine moderne Modellarchitektur, die das klassische U-Net-Backbone durch Transformer-Blöcke ersetzt, um globale Abhängigkeiten besser darzustellen.
-
CLIP (Contrastive Language-Image Pre-training): Ein weit verbreiteter Text-Encoder, der jedoch „charakterblind“ operiert und Wörter nur als ganze Tokens wahrnimmt.
-
LDM (Latent Diffusion Model): Ein Diffusionsmodell, das in einem komprimierten, kontinuierlichen latenten Raum operiert.
-
LLM (Large Language Model): Großes Sprachmodell; wird in modernen Pipelines zunehmend als logische Planungskomponente vor den eigentlichen Bildprozess geschaltet.
-
STRICT (Stress Test of Rendering Images Containing Text): Ein moderner, standardisierter Benchmark zur gezielten Überprüfung und Quantifizierung der Text-Rendering-Qualität in Bildmodellen.
Quellenverzeichnis:
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems (NeurIPS 2020).
-
Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023).
-
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022).
-
Tuo, Y., Xiang, W., He, J., Geng, Y., & Xie, X. (2023). AnyText: Multilingual visual text generation and editing. arXiv-Preprint arXiv:2311.03054.
-
Wang, H., Xu, Y., Li, Y., Li, J., Zhang, C., Wang, J., Yang, K., & Chen, Z. (2025). RepText: Rendering visual text via replicating. arXiv-Preprint arXiv:2504.19724.
Neueste Kommentare